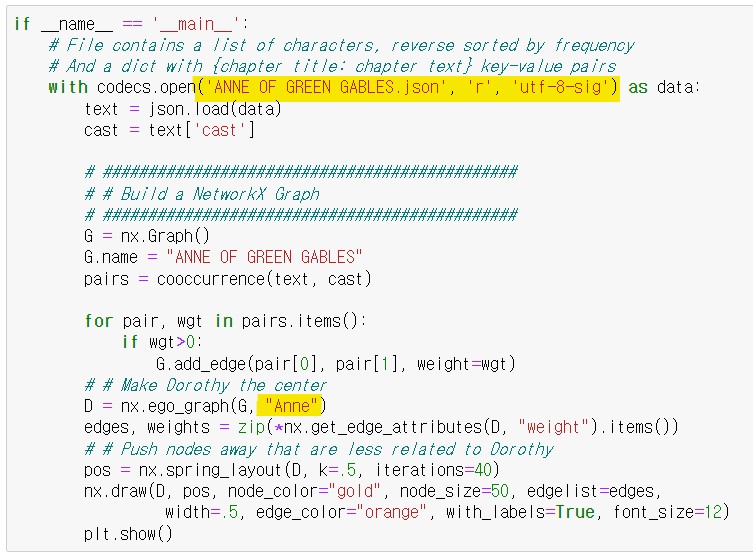
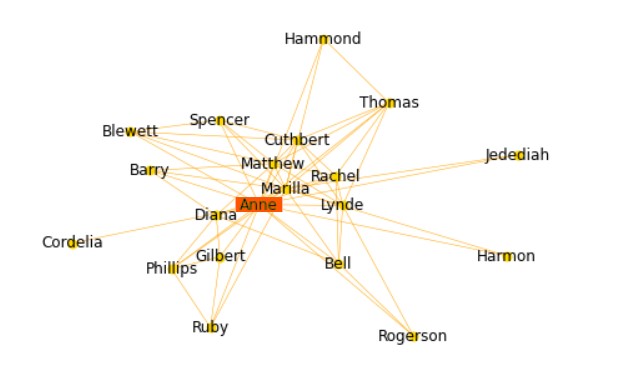
문서가 가지는 모든 단어를 문맥이나 순서를 무시하고 단어에 대해 빈도 값을 부여해 특성(feature) 값을 추출하는 모델이다.
문서 내 모든 단어를 한꺼번에 Bag안에 넣은 뒤에 흔들어서 섞는다는 말로 Bag of Words 모델이라고 한다.
예를 들어 책을 한 권 읽고 대략 어떤 내용인지 알아내야 한다고 생각해보자.
처음부터 차근차근 글을 읽어 나가는 데에는 시간이 오래 걸린다.
이를 좀 더 빨리 할 수 있는 방법은 컴퓨터를 이용해서 책에 나오는 단어의 빈도를 세는 것이다.
책에 어떤 단어가 주로 사용됐는지 알아내면 내용을 유추할 수 있다.
2. Bag of Words 프로세스는?
텍스트 마이닝을 하려면 말뭉치(corpus)를 우리가 다룰 수 있는 수치 형태로 변환해야 한다.
이때 각 수치는 그 텍스트의 특성(feature)을 표현한다.
비유를 들자면, 사람이라는 대상의 특성으로는 이름, 나이, 키, 몸무게 등이 있을 것이다.
각 사람을 구분할 수 있는 것은 이러한 특성의 값들이 달라서다. (ex. Mike, 28 years old, 170cm, 62kg)
우리가 정의한 특성 관점에서, 비슷한 사람끼리는 특성 값이 비슷할 것이다.
그와 마찬가지로 텍스트 마이닝에서는 텍스트의 특성을 정의하고 그 값으로 텍스트를 구분한다.
3. BoW 피처(feature) 벡터화
머신러닝 알고리즘은 일반적으로 숫자형 피처를 데이터로 입력: 받아 동작하기 때문에
텍스트 데이터를 특정 의미를 가지는 숫자형 값인 벡터 값으로 변환해야 한다.
이러한 변환을 피처 벡터화라고 한다.
Bow의 피처 벡터화 2가지 방식
1. 카운트 기반의 벡터화 : 단어 피처에 값을 부여할 때 각 문서에서 해당 단어가 나타나는 횟수, 즉 Count를 부여하는 경우를 말한다. 카운트 벡터화에서는 카운트 값이 높을수록 중요한 단어로 인식된다.
2. TF-IDF(Term Frequency - Inverse Document Frequency) 기반의 벡터화 : 개별 문서에서 자주 나타나는 단어에 높은 가중치를 주되, 모든 문서에서 전반적으로 자주 나타나는 단어에 대해서는 패널티를 주는 방식으로 값을 부여하는 방법이다.
4. 텍스트의 특성(feature)은?
그렇다면 텍스트의 특성은 무엇으로 정의할 수 있을까?
텍스트의 특성은 단어로 표현하고, 특성값은 그 단어가 텍스트에서 나타나는 횟수로 표현한다.
예를들어 "text mining is the process of deriving high quality information from text"라는 문장이 있을 때,
모든 문서의 특성은 같아야 서로 비교할 수 있기 때문에 동일한 단어들로 특성을 표현해야 한다.
다시 말해 전체 말 뭉치에 한번이라도 사용된 단어는 문서에 없더라도 특성에 포함하고 빈도를 0으로 주면 된다.
쉽게 다시 설명하면,
우선 말뭉치(Corpus)와 문서(Document)의 차이점을 알아야 하는데
텍스트 마이닝에서 보통 문장을 문서라고 하고 문장들의 집합을 말뭉치라고 한다.
( ex. 100개의 문장으로 구성된 말뭉치)
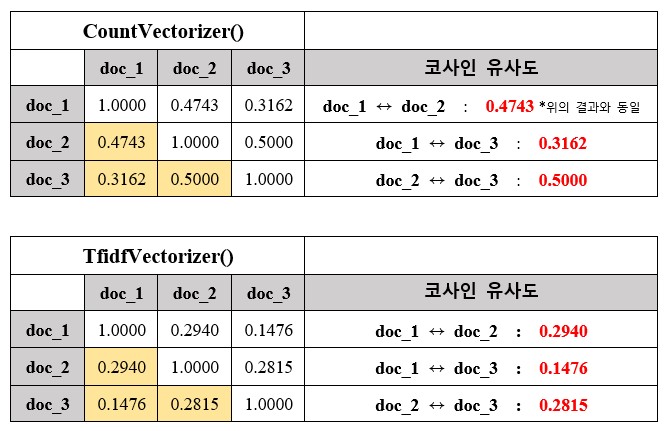
위의 예제에서는 하나의 말뭉치와 3개의 문서가 있는데 각각의 문서의 단어 조합 즉, 특성이 다르다.
문서2에는 'quality', 'deriving' 같은 특성이 포함되어 있지만 문서1과 문서3에는 없다.
이렇게 되면 모든 문서의 특성이 같지 않기때문에 서로 비교 할 수가 없다.
그러므로 전체 말뭉치에 한번이라도 사용된 단어는 특성에 포함하고 빈도를 0으로 준다.
카운트 기반 문서 표현은 문서의 의미를 반영해 벡터를 만드는 과정을 말한다.
위의 결과는 3개의 문서에 대해 특성 벡터를 추출한 결과이고 결과에서 보듯이 각 문서에 없는 특성(단어)들은
0으로 되어 있는 것을 확인할 수 있다. 이렇게 특성이 같아야 서로 비교 할 수 있다.
이렇게 하기 위해서 먼저 대상이 되는 말뭉치에 대해 하나의 단어 집합(Vocabulary)을 구성한다.
그리고 이 단어 집합을 대상으로 각 문서에 대해 빈도를 표시한다.
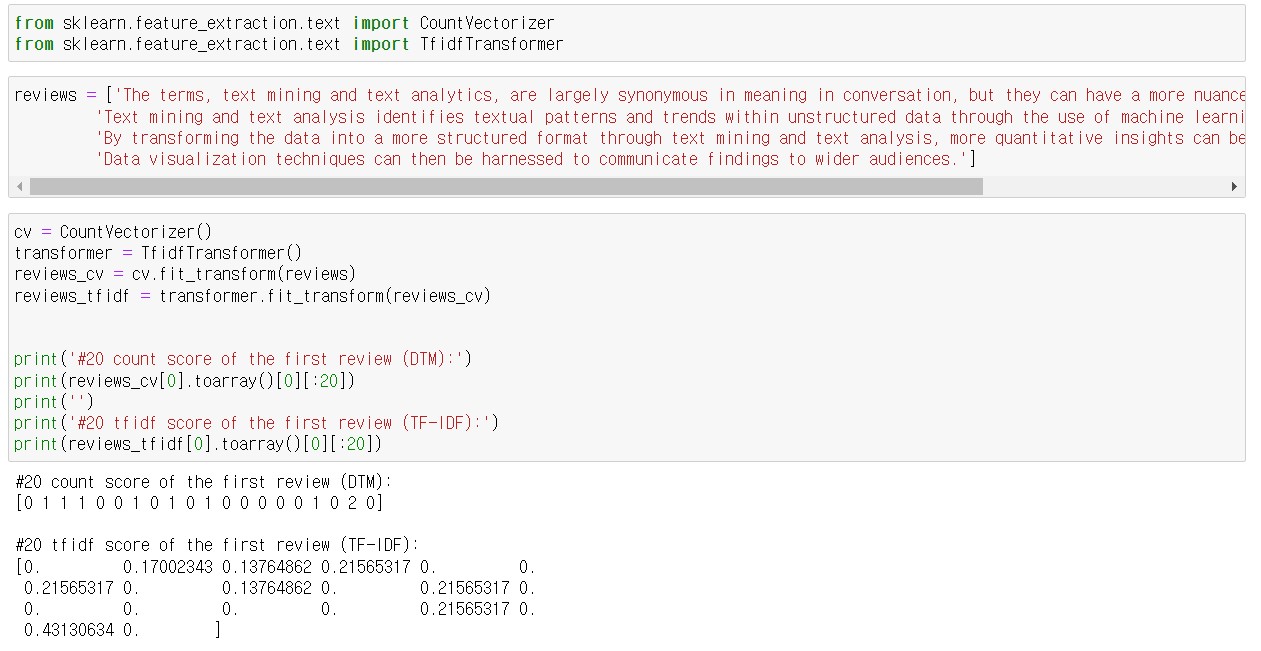
여기서 문제점은 위의 결과와 같이 하나의 문서에서 사용한 단어에 비해 사용하지 않은 단어(0)가 훨씬 많다.
이는 카운트 기반 문서 표현의 본질적인 문제로, 문서를 표현하기 위해 너무나 많은 특성을 사용해야 하고
그 특성중에서 극히 일부만 값을 갖는다.
이와 같이 대부분의 값이 0인 특성 벡터를 희소 벡터(sparse vector)라고 부른다.
정리하자면 텍스트는 우리가 정의한 특성에 대한 특성 값의 집합(혹은 벡터)으로 변환하는데
BoW에서는 단어가 특성이 되고, 이렇게 표현하는 이유는 문서의 단어들을 가방에 넣으면 순서가
사라지기 때문이다. 가방 안의 단어들에 대해 빈도를 계산하여 특성 벡터를 추출한다.
파이썬 텍스트 마이닝 완벽 가이드
* 말뭉치는 '언어 연구를 위해 컴퓨터가 텍스트를 가공, 처리, 분석할 수 있는 형태로 모아 놓은 자료의 집합'을 의미한다. 일반적으로 우리가 텍스트 마이닝을 한다면 그 대상은 하나의 문장 혹은 문서(document)가 아니고 그러한 문장이나 문서들의 집합(corpus)이 된다. 따라서 카운트 기반의 문서표현은 개별 문서가 아닌 말뭉치를 대상으로 한다.
품사 태깅은 형태소(의미를 가진 가장 작은 말의 단위)에 대해 품사를 파악해 부착(tagging)하는 작업을 말한다.
a) 형태소란? 형태소는 '의미를 가진 가장 작은 말의 단위'를 의미한다. 예를 들어 '책가방'이라는 단어는 '책'과 '가방'으로 나눌 수 있고 '가방'을 '가'와 '방'으로 나누면 본래의 뜻을 잃어버린다. 그러므로 '책' 과 '가방'은 형태소로 볼 수 있으나, '가'와 '방'은 형태소라고 볼 수 없다.
b) 품사란? 품사는 명사, 대명사, 수사, 조사, 동사, 형용사, 관형사, 부사, 감탄사와 같이 공통된 성질을 지닌 낱말끼리 모아 놓은 낱말의 갈래'를 말한다.
2. 영어로 된 텍스트에 대한 품사 태깅 _ NLTK
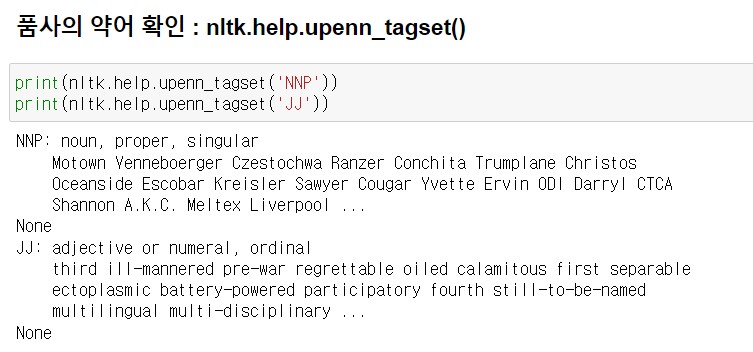
품사의 약어를 잘 모를 경우에는 nltk.help.upenn_tagset()을 사용해 품사 약어의 의미와 설명을 볼 수 있다.
3. 한글로 된 텍스트에 대한 품사 태깅 _ KoNLPy
그렇다면 NLTK로 한국어 문서에 대해서도 품사 태깅도 가능할까? 안된다.
파이썬에서 쓸 수 있는 대표적인 한국어 형태소 분석 및 품사 태깅 라이브러리는 KoNLPy가 있다.
KoNLPy는 Hannanum, Kkma, Komoran, Twitter(Okt), Mecab 이렇게 다섯 종의 형태소 분석기를 제공한다.
보통 Twitter(Okt) 속도가 빨라서 많이 사용하지만 KoNLPy 홈페이지에서 각 분석기 간의 성능을 비교해보고 용도에 맞는