Technology that lets us “speak” to our dead relatives has arrived. Are we ready?
Digital clones of the people we love could forever change how we grieve.
www.technologyreview.com
사랑하는 가족, 연인, 친구를 준비없이 한순간에 잃게 된다면 어떨까?
돌아가신 어머니, 아버지의 목소리가 너무 듣고 싶어진다면?
사랑하는 사람이 떠난 후 우리는 그들의 사진을 벽에 붙이고, 그들의 생일에 산소에 방문하고
우리는 마치 그들이 그곳에 있는 것처럼 그들에게 말하지만 대화는 항상 일방적이었다.
AI 플랫폼 HereAfter는 사망한 사람이 살아 있는 동안 녹음한 음성을 기반으로 사람들이 '대화'를 할 수 있도록 하는
소프트웨어를 설계하였다.
죽은 사람들과 "대화"할 수 있게 해주는 이와 같은 기술은 수십 년 동안 SF의 주류였다.
그러나 이제는 AI와 음성 기술의 발전 덕분에 현실이 되었고 점점 더 쉽게 접근할 수 있게 되었다.
애플의 Siri나 아마존의 Alexa 같은 챗봇 및 음성 비서는 지난 10년 동안 수백만 명의 사람들에게 새로운 첨단 기술에서
일상 생활의 일부가 되었고 일기 예보에서 삶의 의미에 이르기까지 모든 것에 대해 우리의 장치로 이야기한다는 아이디어에
매우 편안한 삶을 살게 되었다.
또한 AI LLM(Large Language Models)은 인간이 기계와 통신할 수 있는 훨씬 더 강력한 방법을 제공하였다.
이 글을 쓴 에디터 Charlotte은 Hereafter 공동 설립자인 James Vlahos가 ''가상 존재"에 대한 온라인 회의에서
연설 하는 것을 보았고 그를 설득하여 그녀의 살아계신 부모님을 대상으로 소프트웨어를 실험할 수 있게 되었다.
우선 첫번째 단계는 인터뷰였다. 실제 표현처럼 보일려면 많은 데이터가 필요하다.
2020년 12월, HereAfter의 Meredith라는 여성이 Charlotte의 부모님을 인터뷰를 하였다.
'그들이 아직 살아 있을 때' 라는 주제를 가지고 작업을 시작하는 Hereafter는 가장 어린 시절의 기억부터, 첫 데이트,
죽은 후 일어날 것이라고 믿는 모든것에 대해 몇 시간 동안 질문을 던진다.
Charlotte와 그녀의 언니는 주어진 질문 외에 좀 더 개인적인 질문을 추가 할 수 있었다.
예를 들어 어떤 책을 좋아하셨나요? 1970년대 영국에서 압도적으로 남성이 많고 특원을 누리는 법조계
엄마는 어떻게 진출하셨나요? 우리가 어렸을 때 함께 하던 게임을 발명하게 된 동기는 무엇입니까?
와 같은 질문등을 추가하였다.
그 후 HereAfter는 질문에 대한 답변을 받아 음성 비서를 만들기 시작하였고 몇 달 후 Charlotte은 Vlahos로 부터
가상의 부모님이 준비되었다는 연락을 받았다.
챗봇(가상의 부모님)은 전화나 Amazon Echo 장치의 Alexa 앱을 통해 통신할 수 있었다.
실제로 대화가 가능했지만 제한적이거나 실수도 있었다.
하지만 가상 버전과 대화할 때마다 실제 부모님과 대화할 수 있다는 생각이 들었다.
하지만 이 챗봇도 많은 위험을 가지고 있다.
이런 서비스는 데이터 이용에 대한 개인 정보 보호와 관련하여 몇 가지 복잡한 윤리적 문제를 가지고 있다.
또한 슬픔의 극심한 단계에서는 비현실감이 강하고 자신이 사랑하던 사람이 사라졌다는 사실을 받아들일 수 없다는 느낌을
받을 수 있고 이러한 종류의 격렬한 슬픔은 정신 질환을 유발 할 수 있다고 전문가들은 경고한다.
HearAfter의 챗봇은 완전히 새로운 대화를 나누는 것이 아니라 누군가의 삶의 이야기,
그 누군가에 대한 기억을 보존하는 것을 목표로 한다.
이 기술이 사람을 재창조하거나 보존한다고 생각하지 않도록 주의해야 한다.
어떤 사람들에게는 사랑하는 사람들이 떠난 후 그들의 목소리를 듣는 것이 애도 과정에 도움이 된다고
임상 심리학자인 Erin Thompson은 말한다.
더 많은 대화를 나눌 수 있는 가상 아바타가 당신이 사랑하고 잃어버린 사람과 연결을 유지하는 가치 있고
건강한 방법이 될 수 있다고 말한다.
특정 사람의 데이터 (주고 받은 메세지, 일기 등)로 훈련시킨 이 챗봇은 특정 사람 쓰던 말투, 이모티콘등을 사용하여
사랑하는 사람을 잃은 슬픈 사람에게 죽었지만 아직 함께 있다는 위로를 준다.
실제로 저널리스트 Jason Fagone은 GPT-3를 기반으로 제작된 Project December 소프트웨어로 죽은 약혼자의
오래된 텍스트, 페이스북 메세지를 이용하여 여자친구 Jessica와 가상 시뮬레이션을 한 Joshua Barbeau 대한 관한 글을 썼다.
사망한 자신의 여자친구를 오랫동안 잊지 못한 Joshua가 Project December 가상 시뮬레이션을 통해서
Jessica와 대화를 하면서 들었던 생각과 느낌, 감정등을 사람들에게 공유하였다.
He couldn’t get over his fiancee’s death. So he brought her back as an A.I. chatbot
The death of the woman he loved was too much to bear. Could a mysterious artificial intelligence website allow him to speak with her once more?
www.sfchronicle.com
사랑하는 사람의 죽음을 준비 할 수 있다면 좋겠지만 갑작스러운 이별을 한 사람들에게 그 사람의 빈자리가
너무 크게 느껴질것이다. 또한 Joshua와 같이 사랑하는 사람의 죽음을 받아들이지 못해 힘들어하거나
그리워 하는 사람도 많을것이다.
이 챗봇이 그런 사람들에게 조금이나마 도움이 될 수 있지 않을까.
'AI' 카테고리의 다른 글
| <Processing> Image-Rasterizer (0) | 2022.10.11 |
|---|---|
| [Google Imagen] A text-to-image diffusion model (0) | 2022.10.09 |
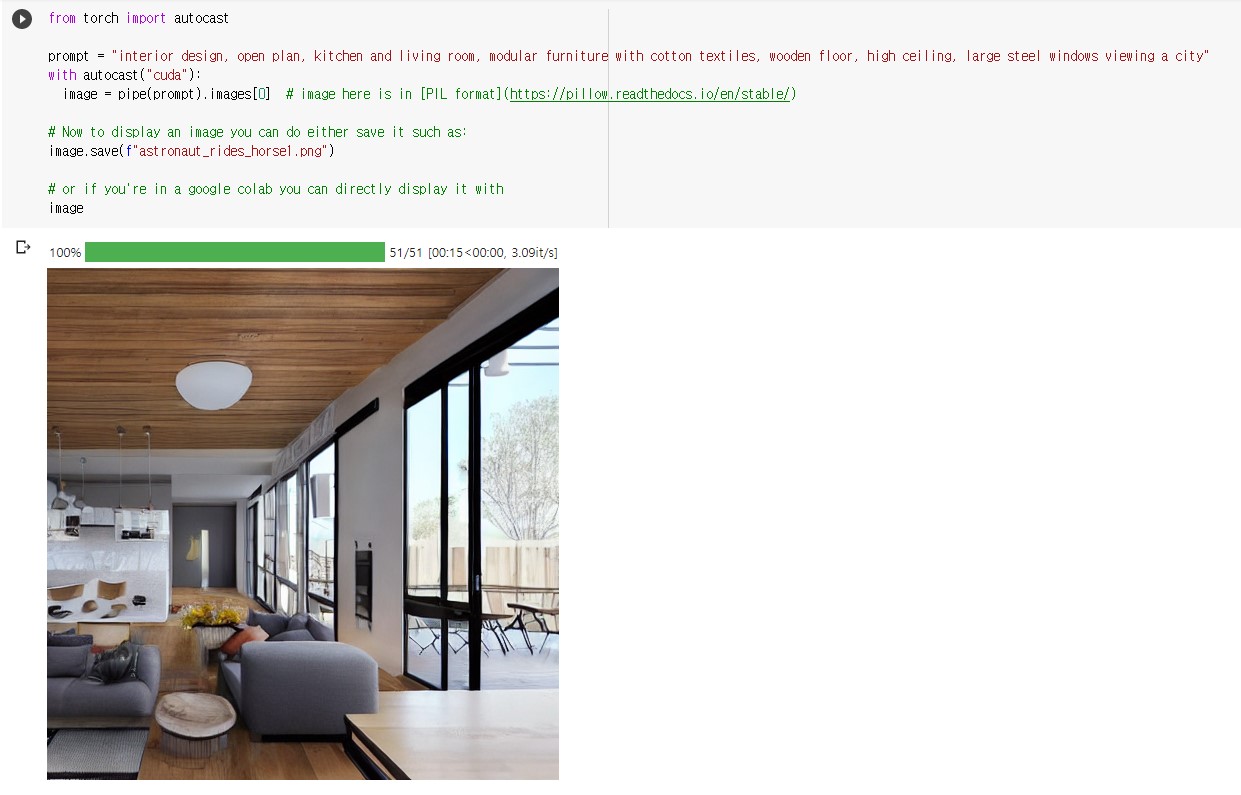
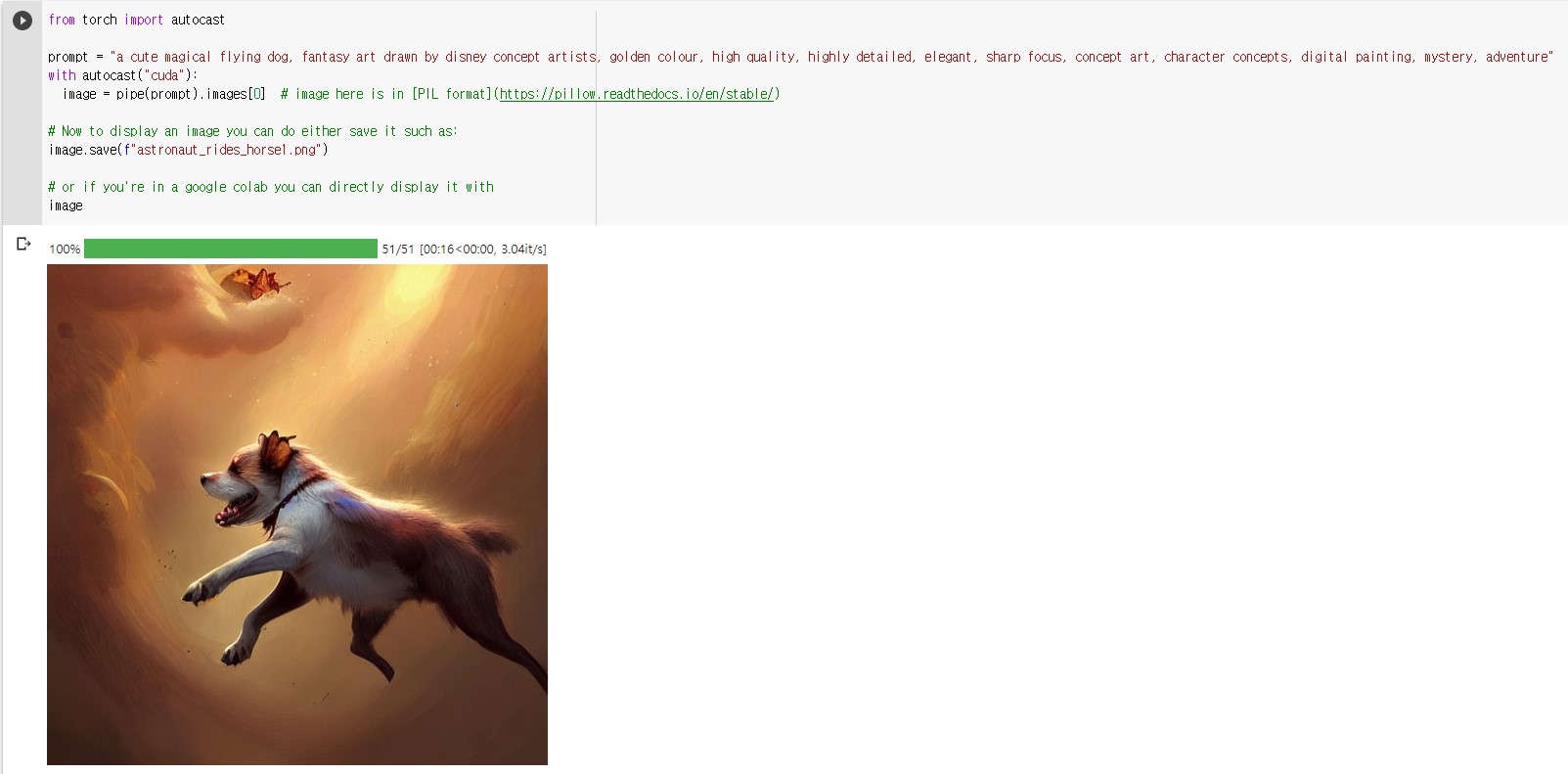
| [Stable Diffusion] 딥러닝 텍스트 이미지 모델 (1) | 2022.10.06 |
| [MIT Technology Review] What does GPT-3 “know” about me? (0) | 2022.09.14 |
| [뉴스 기사] Google Search is changing, in a big way (0) | 2022.08.26 |