
1) 문제 설명

2) 코드
('좋아요' 수 제일 많은 풀이)
3) 코드 설명
① answer = [0] * len(id_list)
# answer 변수에 id_list 갯수 만큼의 0이 있는 리스트를 넣어주었다.
② reports = { x : 0 for x in id_list}
# dictionary = { key : values }
# id_list의 muzi, frodo, apeach, neo를 순차적으로 x로 뽑아서 딕셔너리의 key로 만들고 values는 다 0으로 한다.
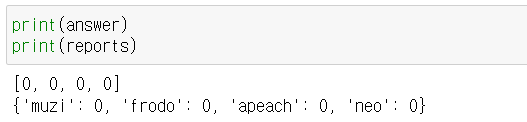
# answer 와 reports를 print 하면 ↓ 이렇게 나온다.
③ for r in set(report):
reports[r.split()[1]] += 1
# set 함수는 집합으로 만들어 주는 함수 즉, 중복된 숫자를 제거할때 사용하는 함수이다.
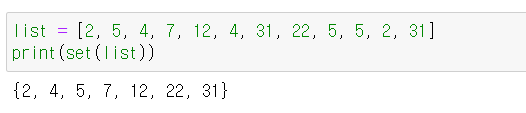
# ↓의 예를 보면 list = [2, 5, 4, 7, 12, 4, 31, 22, 5, 5, 2, 31] 이렇게 2, 4, 5, 31 중복되어 리스트에 들어있다.
set 함수를 사용하여 list를 print 하면 중복된 숫자가 한번만 출력되는 것을 확인할 수 있다.
# set(report) 에서 요소를 하나씩 꺼내서 split 함수를 사용하여 공백을 기준으로 split 한다.
# 공백을 기준으로 split 하면 "muzi frodo" 이렇게 되어 있는게 "muzi", "frodo" 이렇게 둘로 나눠지게 되고 "muzi" 가
[0]번째 "frodo" 가 [1]번째가 된다.
# [1]번째만 뽑아서 그 이름만큼 더해서 합계를 낸다 ( += 1 의미 )
# ↓의 예를 보면 딕셔너리로 철수, 민수, 영희의 시험점수를 입력하였다.
# 민수의 점수를 알고싶다면 scores["민수"] 로 점수를 읽을 수 있고 83점이던 민수의 점수를 88점으로 변경하려면
scores["민수"] = 88 이렇게 가능하다.

# reports[r.split()[1]] += 1 도 동일한 방법으로 reports["muzi"] += 1, reports["frodo"] += 1, report["neo"] += 1
reports["apeach"] 이렇게 하나씩 카운트하여 합계를 나타낸 것을 넣으라는 것이다.

# ↑ 위를 보면 report에서 요소를 하나씩 꺼내서 split 한 다음에 [1]번째 이름에 카운트를 해서 합계를 낸 것이다.
# 첫번째 결과를 보면 report 에서 "muzi frodo"가 꺼내졌고, [1]번째인 frodo를 +1 해줬다.
{ 'muzi' : 0, 'frodo' : 1, 'peach' : 0, 'neo' : 0 }
# 두번째 결과를 보면 report 에서 "muzi neo"가 꺼내졌고, [1]번째인 neo를 +1 해줬고 첫번째 결과의 frodo는 그대로
1이다.
{ 'muzi' : 0, 'frodo' : 1, 'peach' : 0, 'neo' : 1 }
# 세번째 결과를 보면 report 에서 "apeach frodo"가 꺼내졌고, [1]번째인 frodo를 +1 해줘서 frodo가 2가 되었다.
{ 'muzi' : 0, 'frodo' : 2, 'peach' : 0, 'neo' : 1 }
# 네번째 결과를 보면 report 에서 "apeach muzi"가 꺼내졌고, [1]번째인 muzi를 +1 해줬다.
{ 'muzi' : 1, 'frodo' : 2, 'peach' : 0, 'neo' : 1 }
# 마지막으로 report 에서 "frodo neo"가 꺼내졌고, [1]번째인 neo를 +1 해줘서 neo는 2가 되었다.
{ 'muzi' : 1, 'frodo' : 2, 'peach' : 0, 'neo' : 2 }
# report 에서 꺼내는 순서는 랜덤이기에 ("apeach neo" 가 먼저 꺼내질 수 도 있다.) 마지막 결과만 빼고 1-4번째 결과는
바뀔수도 있다.
# print의 위치를 for문 열에 맞춰서 출력을 하면 제일 마지막 결과만 출력이 된다. ↓ 참조.

④ for r in set(report):
if reports[r.split()[1]] >= k:
answer[id_list.index(r.split()[0])] += 1
# set(report) 에서 요소를 하나씩 꺼내서 reports[r.split()[1]] 값, 즉 { 'muzi' : 1, 'frodo' : 2, 'peach' : 0, 'neo' : 2 }
중에서 k 보다 크거나 같으면 (이 문제에서는 k = 2 이므로 frodo와 neo가 해당된다)
answer[id_list.index(r.split()[0]] += 1 이렇게 한다.
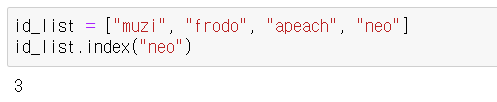
# 밑에 ↓ 결과에서 보면 알 수 있듯이 id_list.index("neo")를 출력하면 리스트에서 "neo"의 위치를 반환한다.
# 리스트는 0부터 시작하므로 "neo"는 id_list의 3번째에 위치해 있다.
# id_list.index(r.split()[0])는 "muzi frodo" 여기서 [0]번째 즉, muzi를 얘기하는 것이므로 [1]번째에
frodo 와 neo를 가지고 있는 요소를 찾고 그 요소의 [0]번째 이름을 찾아서 그 인덱스 자리에 +1을 하라는 말이다
# 다시말해 report = ["muzi frodo","apeach frodo","frodo neo","muzi neo","apeach muzi"] 에서 frodo 와
neo를 [1]번째에 가지고 있는 요소는 "muzi frodo", "apeach frodo", "frodo neo", "muzi neo"이다. 이 요소들의
[0]번째 즉, muzi, apeach, frodo, muzi를 id_list에서 찾아서 이름에 맞는 자리에 +1 씩 해주라는 의미이다.
# id_list = "muzi", "frodo", "apeach", "neo" 순 이므로 muzi = 2, frodo = 1, apeach = 1, neo = 0 이고 이것을 출력하면
그 순서에 맞게 [2, 1, 1, 0] 이 나오는 것이다.
'코딩 연습' 카테고리의 다른 글
| [프로그래머스] 체육복 (python) (0) | 2022.05.10 |
|---|---|
| [카카오] 1차 다트 게임 (python) (0) | 2022.05.04 |
| [프로그래머스] 내적 (python) (0) | 2022.04.28 |
| [프로그래머스] 로또의 최고 순위와 최저 순위 (python) (0) | 2022.04.28 |
| [카카오] 크레인 인형 뽑기 게임(python) (0) | 2022.04.25 |