

'데이터 분석 > 논문 리뷰' 카테고리의 다른 글
| [논문리뷰] Deep Interest Network for Click-Through Rate Prediction (0) | 2022.06.06 |
|---|
| [논문리뷰] Deep Interest Network for Click-Through Rate Prediction (0) | 2022.06.06 |
|---|
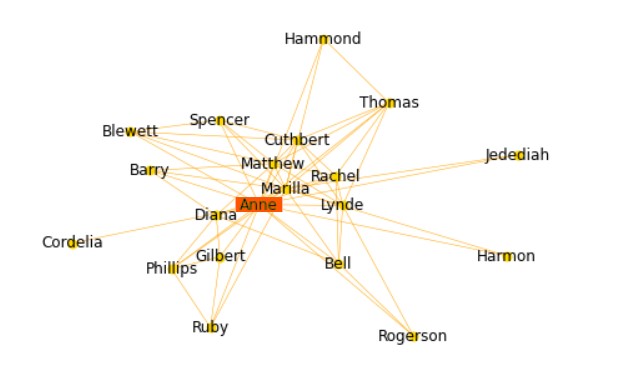
영문 소설 '빨강머리 앤 (Anne of Green Gables)' 을 가지고 주인공 Ann을 중심으로 관계도를 만들어 보았다.
소설 텍스트는 '프로젝트 구텐베르크' 에서 가져왔다.
https://www.gutenberg.org/ebooks/45
사이트로 들어가면 다운받을 수 있는 종류가 많은데 나는 첫번째 Read online(web)으로 들어갔다.

챕터별로 영문 텍스트를 복사 해서 Visual Studio(VS)에 붙여넣기를 했다.
붙여넣기 하기 전에 VS에서 File -> New File -> ANNE OF GREEN GABLES.json 을 만들어주었다.
(파일 저장은 jupyter notebook의 python 파일이 저장되는 곳에 저장했다.)
그러고 나서 밑에 사진처럼 딕셔너리 형식으로 "cast"와 "chapters" 를 만들었다.
참고로 "cast"는 내가 주인공을 찾아 적어 넣었다.
그 다음 코드를 작성하였다.
빨강머리 앤의 주인공 'Anne'을 기준으로 관계도가 그려진 것을 확인할 수 있다.
| 2.8 코사인 유사도(Cosine Similarity) (2) | 2023.02.03 |
|---|---|
| 2.7 TF-IDF (Term Frequency-Inverse Document Frequency) (0) | 2023.01.25 |
| 2.6 문서 단어 행렬(Document-Term Matrix, DTM) (1) | 2023.01.19 |
| 2.5 Bag of Words(BoW) (0) | 2023.01.16 |
| 2.4 품사 태깅(PoS Tagging) (0) | 2023.01.10 |

'넘치는 데이터 속에서 진짜 의미를 찾아내는 법'을 알고 싶어서 빌려본 책.
책은 세가지 질문으로 시작된다.
‘건강검진을 받으면 장수할 수 있다?’
‘아이들이 텔레비전을 많이 보면 성적은 떨어진다?’
‘명문 대학을 졸업하면 연봉이 높다?’
언뜻 보면 세 질문의 정답은 ‘YES’로 보인다.
이 논리가 성립된다면 원인과 결과 즉, 인과관계가 성립된다고 말할 수 있다.
과연 그럴까?
건강검진을 받았기 때문에 장수할 수 있는 것(인과관계)가 아니라
건강검진을 받을 정도로 건강에 대한 의식이 높은 사람일수록 장수하는 것(상관관계)이 아닐까?
텔레비전을 보기 때문에 성적이 떨어지는 것(인과관계)가 아니라
성적이 낮은 어린이일수록 텔레비전을 많이 보는 것(상관관계)이 아닐까?
입학 점수가 높은 대학에 갔기 때문에 수입이 높은 것(인과관계)이 아니라
미래의 수입이 상승할 만한 잠재력이 높은 사람일수록 커트라인이 높은 대학에 다니는 것(상관관계)일 수도 있다.
이렇든 많은 사람들이 ‘인과관계’와 ‘상관관계’를 혼동하여 결과를 도출한다.
인과관계인지 상관관계인지 정확히 구분해 내기 위한 방법론을 ‘인과 추론’이라고 하며
이는 추리와 추정을 통해 결론을 이끌어내는 것을 의미한다.
즉, 두 개의 사실이 각각 원인과 결과인지 평가해 결론을 이끌어내는 것이다.
데이터 분석가로서 인과관계와 상관관계의 차이를 이해하고
‘정말 인과관계가 있는지’ 명확히 하는 훈련을 해두는 것이 중요하다고 생각한다.
이 책은 데이터 해석과 인과 추론의 기법을 흥미로운 사례와 함께 설명한 책이며
저자들이 직접 참여했거나 혹은 유명 석학들의 연구 결과를 토대로 인과 추론의 개념과
상관관계/인과관계에 대한 이해, 데이터 해석이 잘못됐을 때 발생할 수 있는 문제에 대해
쉽고 적절한 비유와 함께 풀어 나간 책이다.
우리가 하는 모든 행동이 데이터가 되는 시대에 데이터 분석 기술도 중요하지만
데이터가 만들어내는 숨겨진 맥락을 읽고 데이터의 분석 결과를 해석하는 기술도 필요하기에
‘인과 추론’은 결국 데이터가 범람하는 시대의 필수 교양이라고 할 수 있다.
어려운 통계 용어를 잘 모르는 사람들도 쉽게 이해하도록 구성된 책이라
데이터 관련 일을 하는 사람이라면 읽어보면 좋을 거 같다.
| <빅데이터 시대, 성과를 이끌어 내는 데이터 문해력> by 카시와기 요시키 (0) | 2022.11.29 |
|---|---|
| <모두 거짓말을 한다> by Seth Stephens-Davidowitz (0) | 2022.11.25 |
| <지속 가능한 세상을 위한 데이터 이야기> by 박옥균 (0) | 2022.10.31 |
| <감으로만 일하던 김 팀장은 어떻게 데이터 좀 아는 팀장이 되었나> by 황보현우, 김철수 (0) | 2022.10.14 |
몇일전에 잠실 롯데시네마(월드타워점)에 영화를 보러갔다왔다.
영화는 일요일 밤 21시30분이었고 우린 18시03분에 입차, 24시 39분(다음날 새벽)에 출차했다.
총 주차 시간은 6시간 36분이었고 주차 요금은 6400원이었다.

그런데 궁금한것이 있었다.
첫째, 롯데시네마 월드타워점 주차 비용은 주말이든 평일이든 상관없이 10분당 200원 (최대 4시간) 이다.
만약 롯데타워몰에 4시간 이상 주차한다면 주차 비용은 어떻게 계산될까?
우선, 롯데시네마를 방문 하기위해서는 롯데월드몰 시네마 구역 주차장에 주차를 해야했다.

또한, 영화관람시 22시이후부터 50% 주차 할인이 적용되어 10분당 100원이다.

자 그럼 쉽게 일요일 오후 18시에 입차하고 24시40분에 출차했다고 가정하자.
18시부터 20시까지는 10분당 500원 (1시간 3000원) 이다.
그리고 20시부터 새벽 24시40분까지는 10분당 200원 (1시간 1200원) 이다.

계산을 하면 원래 주차금액은 11,600원이다. 그림1의 영수증 사진에서의 주차 금액과 동일하다.
그렇다면 어떻게 6,400원이 나왔는지 계산을 해보자.

입차 시간(18시)부터 4시간은 시네마 할인을 받아서 10분당 200원으로 주차 요금이 계산됐고,
22시부터 출차 시간(24시 40분)은 심야 할인을 받아서 10분당 100원으로 주차 요금이 계산됐다.
그래서 총 요금이 6,400원이 되었다.
즉, 영화관람시 4시간 주차 할인 적용은 입차 시간으로 부터 먼저 계산이 되어 지는거 같다.
둘째, 할인 시네마 5,200원은 어떻게 계산된걸까?
다시 정리해서 표를 만들어보면
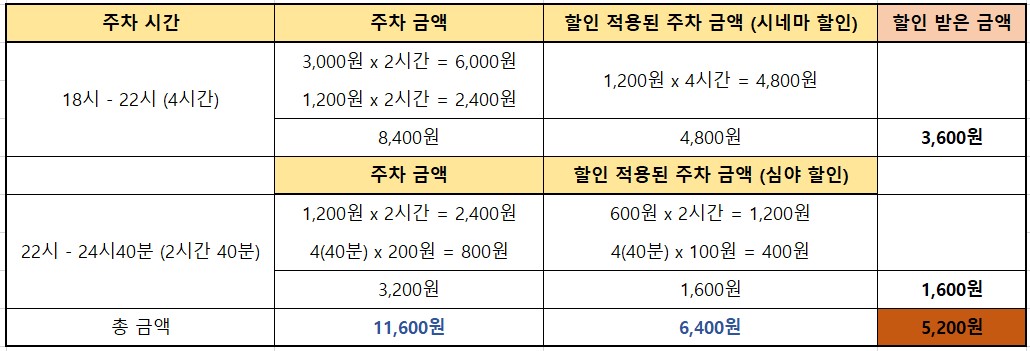
표3을 보면 시네마 할인으로 3,600원, 심야 할인으로 1,600원, 총 5,200원 할인 받은 것을 확인 할 수 있다.
이는 그림1 영수증에 나타난것과 같은 동일한 금액이다. (할인 시네마 5,200원)
| [TED] 거절을 통해 배운 것들 by Jia Jiang, 남형도기자 (0) | 2023.02.01 |
|---|---|
| [매일경제] 긍정적 생각이 사망·심혈관계 위험 낮춘다. (1) | 2023.01.18 |
| [마케팅] Coca-Cola’s Friendly Twist Bottle Campaign (0) | 2022.12.13 |
| [매일경제] 화물연대 파업 (0) | 2022.12.02 |
| [강남도서관] 더불어 읽고 기부하기 (더.읽.기 프로젝트) (0) | 2022.11.14 |
DTM과 TF-IDF를 이용하여 추출한 벡터는 머신러닝 기법을 적용하기 위한 입력으로 사용되어
문서 분류부터 다양한 분야에 활용될 수 있다.
문서 간의 유사도를 측정하여 주어진 문서와 가장 유사한 문서를 말뭉치에서 검색하는데 사용하는 방법도
하나의 예이다.
코사인 유사도는 두 벡터 간의 코사인 각도를 이용하여 구할 수 있는 두 벡터의 유사도를 의미한다.
두 벡터의 방향이 완전히 동일한 경우에는 1의 값을, 90°의 각을 이루면 0, 180°로 반대의 방향을 가지면 -1의 값을 갖게 된다.
즉, 결국 코사인 유사도는 -1 이상 1 이하의 값을 가지며 값이 1에 가까울수록 유사도가 높다고 판단할 수 있다.
이를 직관적으로 이해하면 두 벡터가 가리키는 방향이 얼마나 유사한가를 의미한다.

두개의 벡터인 A와 B에 대해서 구하는 식은 다음과 같다.

예를들어 쉽게 설명하면
doc_1 = "Data is the oil of the digital economy"
doc_2 = "Data is a new oil"
doc_3 = "Data is an information"

위의 그림은 카운트 벡터를 사용하여 doc_1과 doc_2를 벡터화한 결과이다.
이 결과를 가지고 코사인 유사도를 구해보면 아래와 같은 결과가 나온다.

CountVectorizer( )와 TfidfVectorizer( )를 사용해서 코사인 유사도를 구한 결과를 보자.
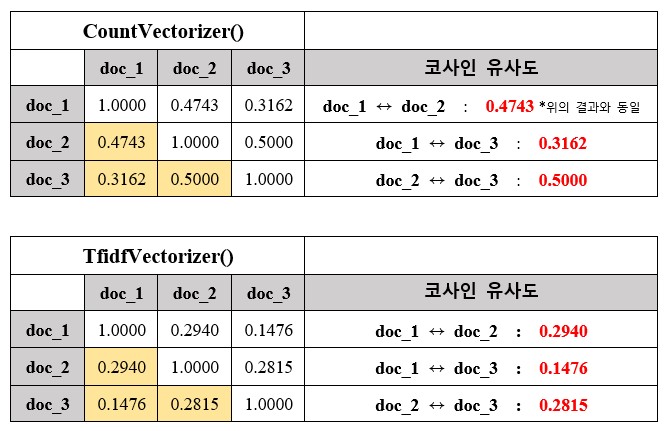
위의 그림과 같이 CountVectorizer( )와 TfidfVectorizer( )의 유사도 결과가 다르다는 것을 확인 할 수 있는데
이는 TfidfVectorizer( )는 문서에서 많이 등장하는 불용어를 제거 하고 계산을 하기 때문이다.
코사인 유사도 소스코드 (깃헙)
GitHub - kaitnam/TIL: Today I Learned
Today I Learned. Contribute to kaitnam/TIL development by creating an account on GitHub.
github.com
https://studymachinelearning.com/cosine-similarity-text-similarity-metric/
| 영문 텍스트(소설) 가지고 관계도 만들기 (0) | 2023.11.13 |
|---|---|
| 2.7 TF-IDF (Term Frequency-Inverse Document Frequency) (0) | 2023.01.25 |
| 2.6 문서 단어 행렬(Document-Term Matrix, DTM) (1) | 2023.01.19 |
| 2.5 Bag of Words(BoW) (0) | 2023.01.16 |
| 2.4 품사 태깅(PoS Tagging) (0) | 2023.01.10 |