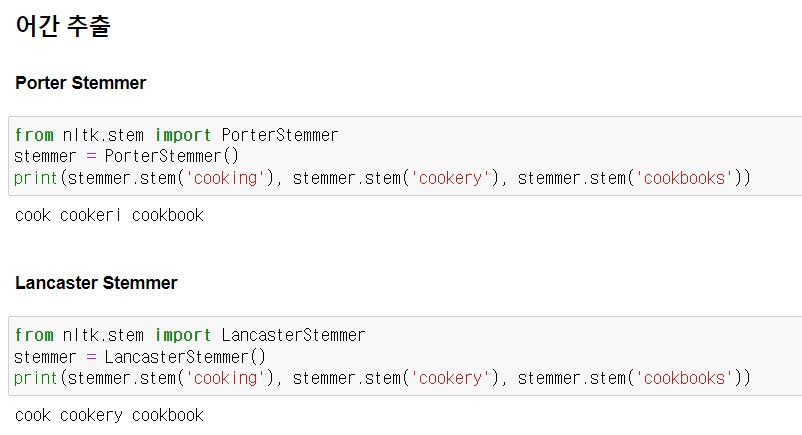
1. 품사 태깅(Part-of-Speech Tagging)이란?
품사 태깅은 형태소(의미를 가진 가장 작은 말의 단위)에 대해 품사를 파악해 부착(tagging)하는 작업을 말한다.
a) 형태소란?
형태소는 '의미를 가진 가장 작은 말의 단위'를 의미한다.
예를 들어 '책가방'이라는 단어는 '책'과 '가방'으로 나눌 수 있고 '가방'을 '가'와 '방'으로 나누면 본래의 뜻을 잃어버린다.
그러므로 '책' 과 '가방'은 형태소로 볼 수 있으나, '가'와 '방'은 형태소라고 볼 수 없다.
b) 품사란?
품사는 명사, 대명사, 수사, 조사, 동사, 형용사, 관형사, 부사, 감탄사와 같이 공통된 성질을 지닌 낱말끼리 모아 놓은
낱말의 갈래'를 말한다.
2. 영어로 된 텍스트에 대한 품사 태깅 _ NLTK

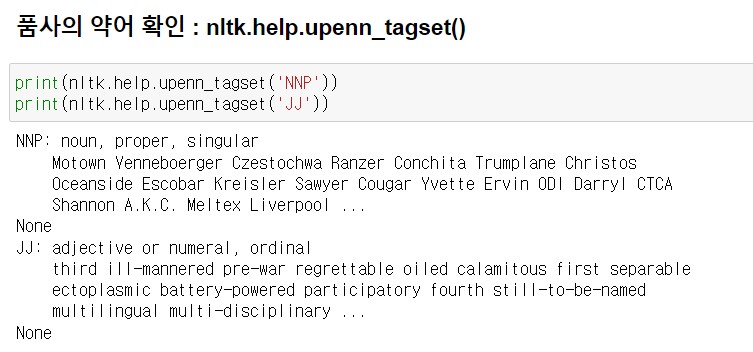
품사의 약어를 잘 모를 경우에는 nltk.help.upenn_tagset()을 사용해 품사 약어의 의미와 설명을 볼 수 있다.
3. 한글로 된 텍스트에 대한 품사 태깅 _ KoNLPy
그렇다면 NLTK로 한국어 문서에 대해서도 품사 태깅도 가능할까? 안된다.
파이썬에서 쓸 수 있는 대표적인 한국어 형태소 분석 및 품사 태깅 라이브러리는 KoNLPy가 있다.
KoNLPy는 Hannanum, Kkma, Komoran, Twitter(Okt), Mecab 이렇게 다섯 종의 형태소 분석기를 제공한다.
보통 Twitter(Okt) 속도가 빨라서 많이 사용하지만 KoNLPy 홈페이지에서 각 분석기 간의 성능을 비교해보고 용도에 맞는
분석기를 선택하여 사용한다. 참고로 Mecab은 윈도우를 지원하지 않는다.


REFERENCE
파이썬 텍스트 마이닝 완벽 가이드(2022)
'데이터 분석 > 자연어 처리' 카테고리의 다른 글
| 2.6 문서 단어 행렬(Document-Term Matrix, DTM) (1) | 2023.01.19 |
|---|---|
| 2.5 Bag of Words(BoW) (0) | 2023.01.16 |
| 2.3 정규화(Nomalization) (0) | 2023.01.09 |
| 2.2 토큰화(Tokenization) (0) | 2023.01.09 |
| 2.1 정제(Cleaning) (0) | 2023.01.09 |